.NET is a strongly-typed object-oriented language, and it is my firm belief that everything we do within it should be strongly-typed and object-oriented in design. A trivial example would be to use the Uri class when dealing with URLs rather than simply passing strings around.
A central theme in object-orientation is encapsulation, which, in layman’s terms, I take to mean “when modelling a particular type of granular thing, the code for that thing should be contained in a single place”. There are a whole host of reasons why encapsulation is good practice, not least that it makes it really easy to change the way an aspect of the code works if changes only have to be made in one place. Better still, if things are encapsulated and strongly-typed, code changes that break other functionality can be found simply by recompiling, rather than having to execute the entire codebase looking for runtime errors.
In my opinion, interactions with standard .NET configuration files should be encapsulated and strongly-typed. Sure, it is possible to access configuration settings by littering code with calls to AppSettingsReader or ConfigurationManager, but this is neither encapsulated nor strongly-typed. If the return type for a setting appearing in many places in the code needed to change and AppSettingsReader/ConfigurationManager had been used throughout the code, this change would break existing code, and worst still, broken code would only be found at runtime. “Find and replace” could be used to find every instance of the setting in the code, but this is hardly ideal and may not find all instances if another coder had been clever and used constants for the key names. Similarly, if the way that configuration values were served needed to be changed, for instance by switching from the standard .NET configuration model to some other type of configuration provider such as a database you’d have to make changes throughout the code-base.
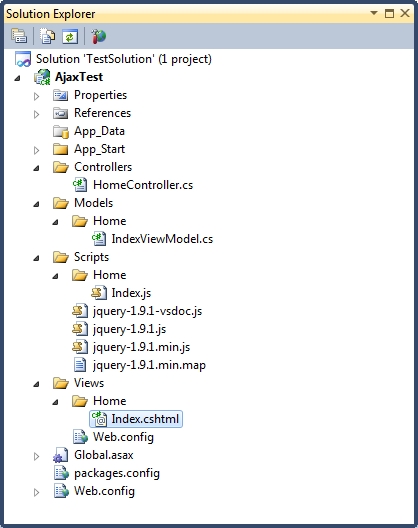
Keeping code to access the configuration file in one place feels like a much more elegant solution. So, how do I normally do this? Well, let’s assume an application with two UIs (User Interfaces) and an API layer (Application Programming Interface) as follows:
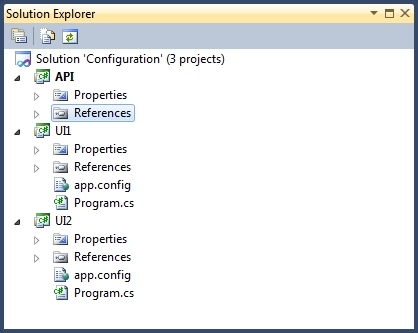
Note that the example solution in this post has been included on GitHub here:
https://github.com/stevebarker333/Encapsulated-Strongly-Typed-Configuration-Files
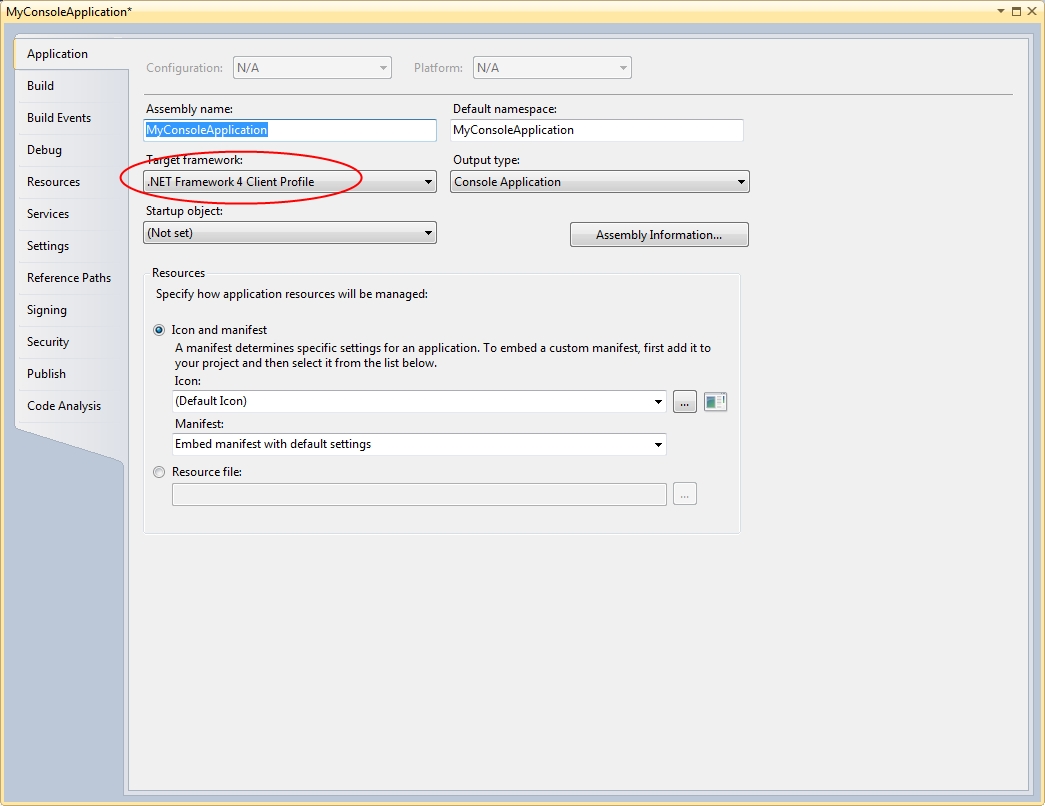
In this example, both UIs are console applications, although in reailty these could be anything, including Windows Services, websites or Windows Applications. (Beware the .NET Framework 4 Client Profile issue if you are going to follow this example yourself!)
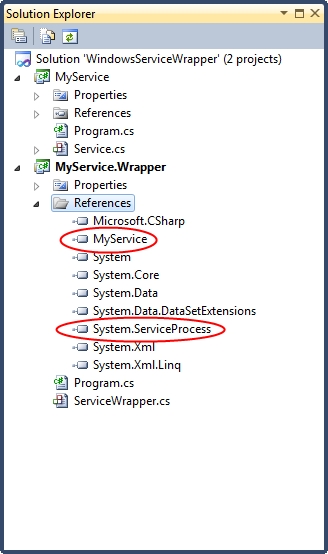
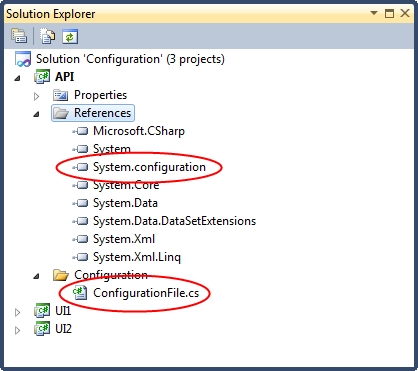
As configuration is owned at the level of the executing assembly, classes to encapsulate configuration settings should exist in the UI projects. However, these classes will share underlying functionality to interact with the configuration files, and so we create a base class in the API project from which all executable-level configuration file classes inherit:
using System;
using System.Configuration;
namespace API.Configuration
{
public abstract class ConfigurationFile
{
private readonly AppSettingsReader appSettingsReader = new AppSettingsReader();
protected string ReadString(string key)
{
try
{
return (string)appSettingsReader.GetValue(key, typeof(string));
}
catch (Exception exception)
{
var message = string.Format("Could not read key {0} from configuration file", key);
throw new ConfigurationErrorsException(message, exception);
}
}
protected int ReadInt(string key)
{
try
{
var value = this.ReadString(key);
return int.Parse(value);
}
catch (Exception exception)
{
var message = string.Format("Could not read an int from key {0} in the configuration file", key);
throw new ConfigurationErrorsException(message, exception);
}
}
protected Uri ReadUri(string key)
{
try
{
var value = this.ReadString(key);
return new Uri(value);
}
catch (Exception exception)
{
var message = string.Format("Could not read a Uri from key {0} in the configuration file", key);
throw new ConfigurationErrorsException(message, exception);
}
}
}
}
Note that all settings are first read as strings using the ReadString method. Other strongly-typed values are then derived from this method. I’ve included ReadInt and ReadUri functionality. More methods can be added to the base class as they are needed, but by the laws of YAGNI, don’t try and second guess every type your application will need up-front!
This class should be placed in a folder called Configuration to get the namespace shown. Additionally, a reference to System.Configuration will need to be added to access the exception classes from within our new base class:
We can now start adding configuration at UI level. Here is my configuration file in UI1:
<?xml version="1.0"?>
<configuration>
<appSettings>
<!-- UI1 Specific Settings -->
<add key="UI1String" value="UI1.String"/>
<add key="UI1Int" value="1"/>
<add key="UI1Uri" value="http://www.ui1.com"/>
<!-- Settings Required By API -->
<add key="CoreString" value="Core.String"/>
<add key="CoreInt" value="0"/>
<add key="CoreUri" value="http://www.core.com"/>
</appSettings>
</configuration>
…and for UI2:
<?xml version="1.0"?>
<configuration>
<appSettings>
<!-- UI2 Specific Settings -->
<add key="UI2String" value="UI2.String"/>
<add key="UI2Int" value="2"/>
<add key="UI2Uri" value="http://www.ui2.com"/>
<!-- Settings Required By API -->
<add key="CoreString" value="Core.String"/>
<add key="CoreInt" value="0"/>
<add key="CoreUri" value="http://www.core.com"/>
</appSettings>
</configuration>
In order to simulate the kinds of scenarios that occur in enterprise solutions, I’ve included settings specific to the executing assembly and shared settings that are required by the API in each configuration file. An example of this would be a web-UI that needs a configuration setting as to how many search results to show on each page of paged search results, with an API responsible for performing the search which needs a configuration setting containing the database connection string to search against.
We can now write our strongly-typed encapsulated configuration file classes in each of the UIs. They have been added to each UI project as follows, along with references to the API project:
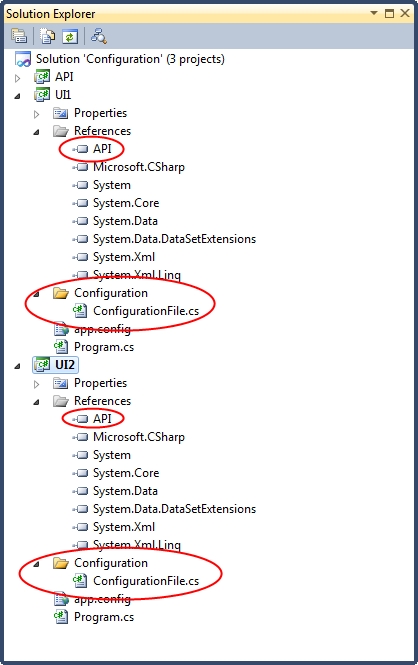
Here is the class for UI1:
using System;
namespace UI1.Configuration
{
public class ConfigurationFile : API.Configuration.ConfigurationFile
{
public string UI1String
{
get
{
return this.ReadString("UI1String");
}
}
public int UI1Int
{
get
{
return this.ReadInt("UI1Int");
}
}
public Uri UI1Uri
{
get
{
return this.ReadUri("UI1Uri");
}
}
public string CoreString
{
get
{
return this.ReadString("CoreString");
}
}
public int CoreInt
{
get
{
return this.ReadInt("CoreInt");
}
}
public Uri CoreUri
{
get
{
return this.ReadUri("CoreUri");
}
}
}
}
…and for UI2:
using System;
namespace UI2.Configuration
{
public class ConfigurationFile : API.Configuration.ConfigurationFile
{
public string UI2String
{
get
{
return this.ReadString("UI2String");
}
}
public int UI2Int
{
get
{
return this.ReadInt("UI2Int");
}
}
public Uri UI2Uri
{
get
{
return this.ReadUri("UI2Uri");
}
}
public string CoreString
{
get
{
return this.ReadString("CoreString");
}
}
public int CoreInt
{
get
{
return this.ReadInt("CoreInt");
}
}
public Uri CoreUri
{
get
{
return this.ReadUri("CoreUri");
}
}
}
}
Note that each configuration file inherits from our shared base class so that it can access the ReadString (and similar) methods defined earlier. As the core/shared settings are shared with the API, then there is an argument for putting the property getters for these properties in the base configuration file class. However, I would argue against this approach as it means the API is dictating how the UI must organise its configuration file. If you’re comfortable with this approach then that’s fine; however I prefer to use an interface in the API to enforce the existence of shared settings in each UI. This allows the UI developer free choice to use any key names they deem fit for core settings. Let’s create this now in the following location:
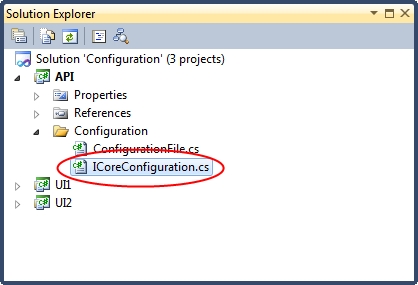
The interface is as follows:
using System;
namespace API.Configuration
{
public interface ICoreConfiguration
{
string CoreString { get; }
int CoreInt { get; }
Uri CoreUri { get; }
}
}
This interface is then applied to each of the configuration file classes in the UI:
using System;
namespace UI1.Configuration
{
public class ConfigurationFile : API.Configuration.ConfigurationFile, API.Configuration.ICoreConfiguration
{
...
}
}
using System;
namespace UI2.Configuration
{
public class ConfigurationFile : API.Configuration.ConfigurationFile, API.Configuration.ICoreConfiguration
{
...
}
}
The ground work has now all been done. All that remains is to put some example code into the UIs and API to demonstrate how our configuration classes and used, and that they do indeed pick up the correct settings.
I’ve added a class to the API to access the core settings:
…which looks as follows:
using API.Configuration;
namespace API
{
using System;
public class Widget
{
private readonly ICoreConfiguration configuration;
public Widget(ICoreConfiguration configuration)
{
this.configuration = configuration;
}
public void DoSomething()
{
Console.WriteLine(configuration.CoreString);
Console.WriteLine(configuration.CoreInt);
Console.WriteLine(configuration.CoreUri);
}
}
}
Note that it is constructed with the type ICoreConfiguration so that it can use the core configuration settings without caring how they’ve be implemented. (Note also that this approach is still valid when using Dependency Injection, which I’ll cover in a future post.)
I’ve also included the following code in the Program class of UI1:
using System;
using UI1.Configuration;
using API;
namespace UI1
{
public static class Program
{
public static void Main()
{
var configurationFile = new ConfigurationFile();
Console.WriteLine(configurationFile.UI1String);
Console.WriteLine(configurationFile.UI1Int);
Console.WriteLine(configurationFile.UI1Uri);
var widget = new Widget(configurationFile);
widget.DoSomething();
Console.ReadLine();
}
}
}
…and the following code in the Program class of UI2:
using System;
using UI2.Configuration;
using API;
namespace UI2
{
public static class Program
{
public static void Main()
{
var configurationFile = new ConfigurationFile();
Console.WriteLine(configurationFile.UI2String);
Console.WriteLine(configurationFile.UI2Int);
Console.WriteLine(configurationFile.UI2Uri);
var widget = new Widget(configurationFile);
widget.DoSomething();
Console.ReadLine();
}
}
}
Running UI1 yields:
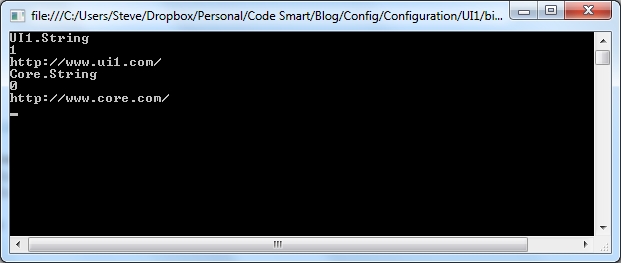
…and running UI2 yields:
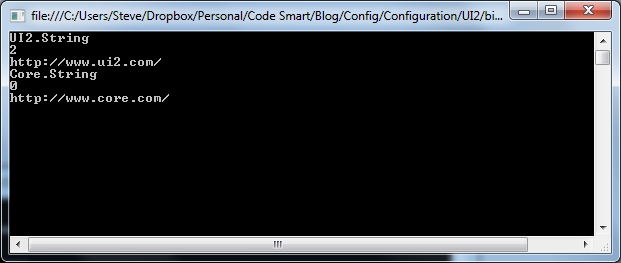
…both as expected.
So, that concludes my exploration of strongly-typed encapsulated configuration files. Although it’s a bit more effort to implement than directly accessing the .NET configuration classes throughout code, it is more logical and far less brittle.
A final note: the .NET Framework automatically caches configuration file values in memory so there is no performance gain from storing configuration values in local class variables within each of our strongly-typed configuration file classes.
Update: As mentioned above, I’ve now extended the above by incorporating dependency injection. See my new post entitled Encapsulated and strongly-typed access to .NET configuration files with dependency injection.