This is the second post in my “Aides-Memoires” category. It’s a bit more complex than my first aides-memoires post on linking JavaScript and CSS, but still pretty basic.
This time I’m tackling the NOT EXISTS query in SQL. Again this is something that I often forget the syntax for and have to Google.
Aside: I haven’t actually had to write a NOT EXISTS query for a number of years now, and with the proliferation of ORMs such as NHibernate and Microsoft Entity Framework I rarely write raw SQL now anyway. However, there are always going to be times when highly complex queries and operations are required, and when execution time is paramount. At those times the most efficient way to get the job done is often to execute SQL directly on the database server using stored procedures, particularly when temporary tables and indexes are required.
For those moments, here’s how to write a NOT EXISTS query…
Note that I’m using T-SQL in SQL Server for these examples, although they will probably work with most relational databases without too much tweaking given the basic nature of the SQL used.
First let’s make some tables:
CREATE TABLE [Table1]
(
[Id] [int] IDENTITY(1,1) NOT NULL,
[Name] [varchar](100) NOT NULL,
CONSTRAINT [PK_Table1] PRIMARY KEY CLUSTERED
(
[Id] ASC
)
)
CREATE TABLE [Table2]
(
[Id] [int] IDENTITY(1,1) NOT NULL,
[Name] [varchar](100) NOT NULL,
CONSTRAINT [PK_Table2] PRIMARY KEY CLUSTERED
(
[Id] ASC
)
)
Now we populate some test data. Note that records are missing from Table2:
TRUNCATE TABLE Table1
TRUNCATE TABLE Table2
INSERT INTO Table1 (Name) VALUES ('One')
INSERT INTO Table1 (Name) VALUES ('Two')
INSERT INTO Table1 (Name) VALUES ('Three')
INSERT INTO Table1 (Name) VALUES ('Four')
INSERT INTO Table1 (Name) VALUES ('Five')
INSERT INTO Table2 (Name) VALUES ('One')
INSERT INTO Table2 (Name) VALUES ('Four')
INSERT INTO Table2 (Name) VALUES ('Five')
SELECT * FROM Table1
SELECT * FROM Table2
Note that I am clearing down the tables each time I add data to ensure a clean starting position, and returning the contents of both tables to show what’s been added. Running the query gives the following results:
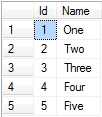
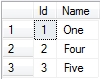
To find rows that exist in Table1 but not Table2, use the following:
SELECT
Name
FROM
Table1 T1
WHERE
NOT EXISTS
(
SELECT
Name
FROM
Table2 T2
WHERE
T1.Name = T2.Name
)
As expected, this returns the following results set:
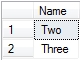
Finally, to find missing rows and insert them into Table2, use the following:
INSERT INTO Table2
(
Name
)
SELECT
Name
FROM
Table1 T1
WHERE
NOT EXISTS
(
SELECT
Name
FROM
Table2 T2
WHERE
T1.Name = T2.Name
)
On execution, this reports:
(2 row(s) affected)
…and a quick look into the Table2 using:
SELECT * FROM Table2
Returns:
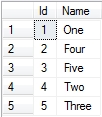
…as expected. Note that the values are in an odd order, proving that Two and Three were inserted last.




